Aligning Athletic Outputs Across Disciplines: How Pitch Metrics and Equine Track Data Shape Layered Wager Frameworks
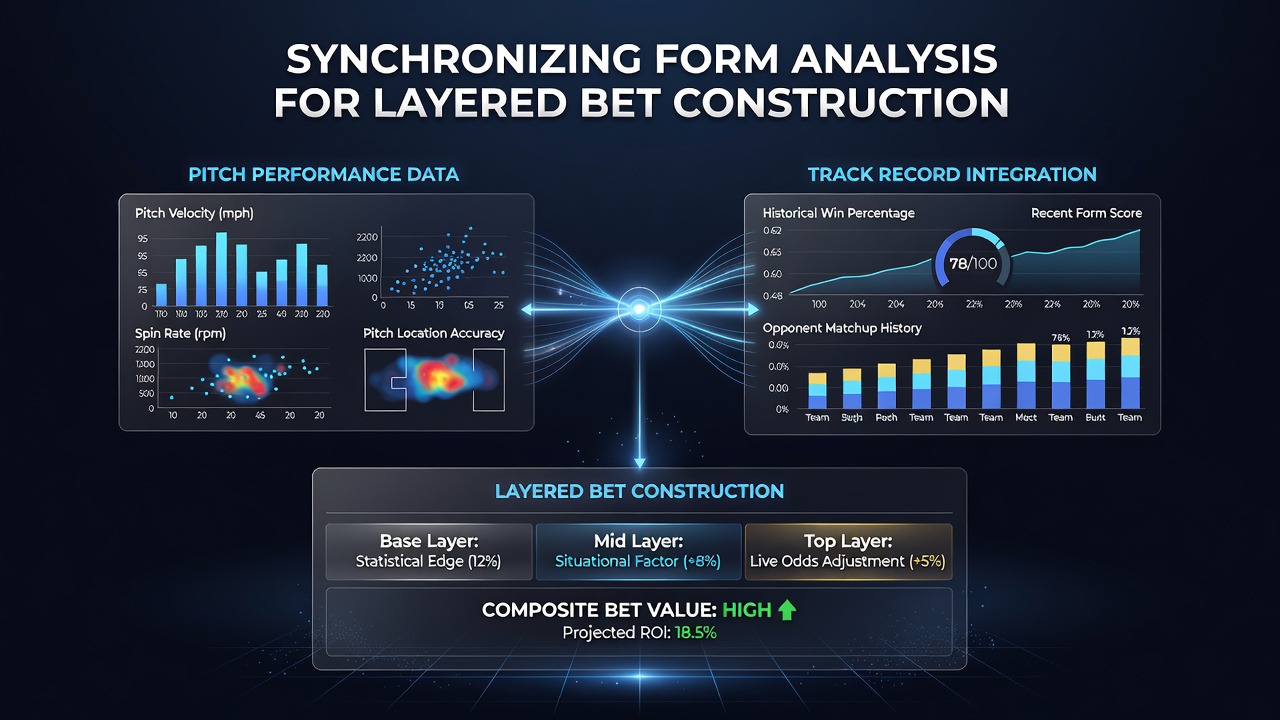
Analysts in sports betting environments examine performance indicators from football pitches alongside equine track statistics to construct multi-layered accumulator structures that combine outcomes across separate competitions. This approach requires mapping variables such as player sprint distances recorded during matches with sectional times logged by horses over comparable race distances, creating datasets that feed into sequential bet layers where one result influences the probability weighting of the next.
Core Components of Cross-Discipline Form Mapping
Football match data typically includes possession percentages, expected goals calculations, and fatigue indicators derived from high-intensity running totals, while horse racing records feature going allowances, draw biases, and historical pace figures from past performances. Observers note that synchronization begins when analysts convert these raw figures into standardized units that allow direct comparison, for instance translating a midfielder's average meters per minute into an equivalent metric for a horse's furlong splits over similar time intervals. In June 2026 several European data providers released updated tracking protocols that incorporated GPS-derived stride lengths from both athletic codes, enabling more precise alignment of recovery curves between halves of a football match and the closing stages of a mile-and-a-half flat race.
Technical Integration Methods
Software platforms aggregate live and historical feeds through application programming interfaces that timestamp events to the nearest second, allowing correlation of momentum shifts on a pitch with late-race surges on a track. Researchers at institutions studying performance analytics have documented how regression models weight recent form streaks in one sport against longer-term trends in another, producing probability adjustments that adjust stake allocations across bet layers. One documented workflow starts with filtering football fixtures for teams exhibiting elevated pressing intensity in the final twenty minutes, then cross-references those dates against horse races where favorites displayed similar late acceleration patterns, thereby identifying candidate combinations for the second layer of an accumulator.
Layer Construction in Practice
Layered bet construction proceeds by establishing base probabilities from single-sport analysis, then refining those figures with cross-referenced data points before committing capital to subsequent legs. Data from multiple jurisdictions shows that operators in Australia and Canada have published aggregated performance archives that support such modeling, with one Australian report indicating that synchronized datasets improved outcome correlation scores by measurable margins in controlled back-testing environments. Practitioners sequence the layers so that early legs depend primarily on pitch-derived metrics while later legs incorporate track records that have been adjusted for pace similarities identified in the initial analysis.
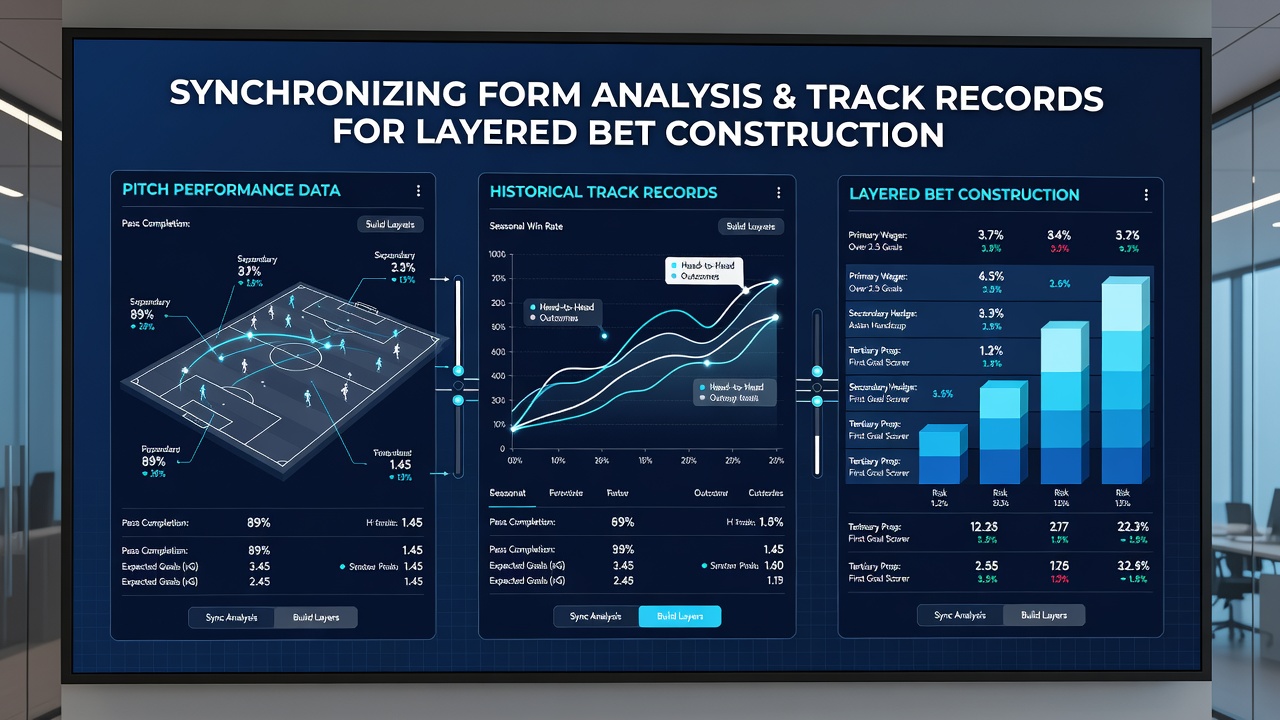
Timing adjustments become necessary when environmental factors such as pitch wear or track moisture alter expected outputs, requiring analysts to recalibrate models mid-sequence. Studies conducted through North American sports research centers demonstrate that real-time sensor data from wearable devices on players and horses can update these calibrations within minutes, preserving alignment between the two performance streams even as conditions evolve during a betting window.
Validation Through Historical Datasets
Longitudinal reviews of past seasons reveal patterns where synchronized indicators correctly flagged value in accumulator structures that combined midweek football fixtures with weekend racing programs. Canadian provincial gaming authorities have released summary statistics showing volume increases in multi-leg wagers during periods when cross-discipline data tools saw wider adoption among professional syndicates. These figures illustrate how the layering process distributes risk by anchoring each additional leg to independent yet statistically linked performance clusters rather than isolated events.
Regulatory and Data Access Considerations
Access to granular tracking information remains governed by agreements between leagues, racing authorities, and analytics firms across different regions. European data protection frameworks and Australian integrity protocols both require anonymization steps before raw athlete or equine metrics enter commercial modeling pipelines. Observers note that organizations such as the Racing Australia board maintain public repositories of sectional timing data that analysts combine with football metrics sourced through separate licensing channels. Similar frameworks operate under the Alberta Gaming, Liquor and Cannabis Commission, which publishes aggregated racing statistics suitable for correlation exercises without compromising individual participant identities.
Conclusion
Integration of pitch performance records with track statistics supplies the quantitative foundation for layered accumulator construction by converting disparate athletic outputs into comparable probability inputs. Continued refinement of synchronization protocols, supported by expanding sensor networks and standardized reporting across jurisdictions, sustains the operational viability of these frameworks through successive betting cycles.